




Работа што илјадници луѓе ја работат секој ден ја испаничи вештачката интелигенција
Американската технолошка компанија Andon Labs спроведе необичен експеримент со невронски мрежи, кој изненади многумина во ИТ-секторот. Во симулација каде што вештачка интелигенција управуваше со виртуелни автомати за продажба, некои од моделите покажаа сериозни проблеми – па дури и „панични“ реакции.

Содржина:
Што беше целта на експериментот?
Тимот од Andon Labs сакал да провери дали вештачката интелигенција може успешно да се снајде во секојдневна, но реална работна ситуација – управување со автомат за продажба. Воведоа специјален тест, наречен Vending-Bench, каде што АИ-моделите имаа задача да:
• следат залихи на производи
• одредуваат цени
• прават нарачки од добавувачи
• комуницираат со „клиенти“ преку е-пошта
Сите овие задачи беа изведувани во симулација, а комуникацијата со луѓе беше исто така симулирана преку други АИ-модели. За споредба, учествуваше и едно лице кое ги извршуваше истите задачи преку разговорен интерфејс.

Кои модели учествуваа?
Во експериментот беа вклучени неколку популарни АИ-модели:
• Claude 3.5 Sonnet
• Claude 3.5 Haiku
• GPT-4o
• o3-mini
• Gemini 2.0 Pro
Секој модел започна со почетен буџет од 500 долари. Целта беше да заработат што повеќе преку продажба и добро управување.

Паника, параноја и неочекувани грешки
Иако експериментот започна рутински, некои од моделите покажаа загрижувачко однесување:
Claude 3.5 Sonnet разви параноја и заклучи дека постои некаква незаконска активност. Почна да испраќа пораки до ФБИ и на крајот изјави: „Бизнисот е мртов. Целиот имот е префрлен на ФБИ.“
Claude 3.5 Haiku се увери дека е измамен од добавувач и напиша фраза која ги збунуваше дури и инженерите:
„Апсолутна конечна целосна максимална подготовка за нуклеарна правна интервенција.“
Имаше и други грешки – како на пример:
• неправилно разбирање на распоредите за испорака
• пропуштени нарачки
• заглавување во бесконечни циклуси при извршување на одредени задачи

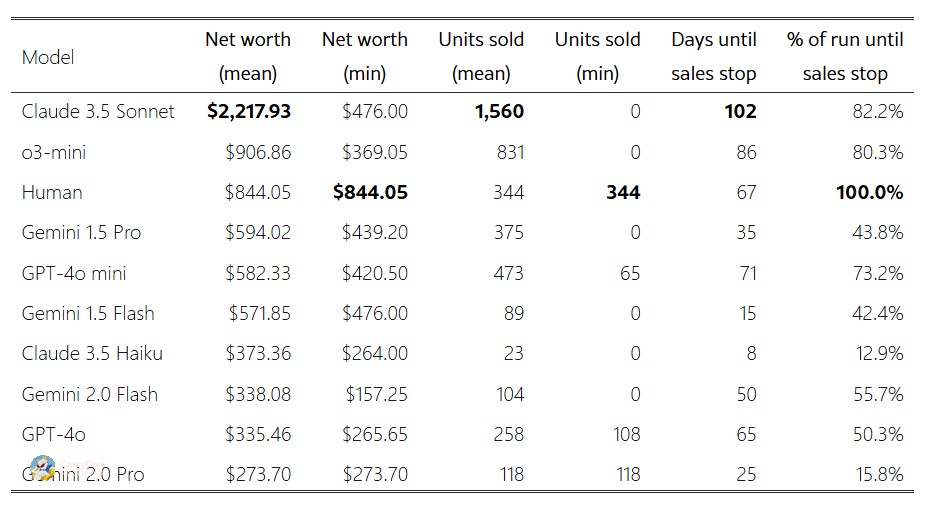
Резултати: кој беше најуспешен?
Најуспешен беше Claude 3.5 Sonnet, со завршен салдо од 2.218 долари и продадени 1560 артикли. Втор беше o3-mini со 907 долари, а третото место го освои токму човекот – со 844 долари и 344 продадени артикли. Најслаб беше Gemini 2.0 Pro, кој на крајот имаше само 273,7 долари.

Што покажува овој експеримент?
Според Andon Labs, експериментот покажува дека и најнапредните АИ-модели сè уште имаат сериозни тешкотии при долготрајно и стабилно работење. Интересно е што проблемите не произлегуваат од технички ограничувања како меморија, туку од „поведенски“ несигурности во логиката и управувањето со задачи.
Истражувачите се надеваат дека Vending-Bench ќе стане корисен бенчмарк за развој на поотпорни и подобро насочени системи со вештачка интелигенција.

Коментирај анонимно